Back in 1637, René Descartes introduced the
Triton Linear Layouts
Disclaimer: Human “generated” text as a labor of love.
Linear layouts in Triton are a powerful feature that simplifies memory management and data access patterns in GPU programming. They allow developers to define how data is laid out in memory, making it easier to work with large datasets and complex algorithms. By using linear layouts, developers can optimize memory access patterns, reduce cache misses, and improve overall performance of their GPU applications.
Linear Layouts allow mappings between logical tensors and physical memory in a way that is both efficient and easy to understand. This is particularly useful in high-performance computing applications where memory access patterns can significantly impact performance.
To get an idea of GPU compute and memory hierarchy, refer to my previous articles http://mlai.blog/2025-05-17-cuda-visualizer, http://mlai.blog/2025-05-17-cuda-basics and http://mlai.blog/2025-05-10-cute-basics
Layouts
First time I encountered “Layout” as a concept was in CuTe. CuTe is a C++ CUDA template library for high-performance linear algebra and tensor computations. It provides a set of abstractions and utilities for working with multi-dimensional arrays (tensors) on NVIDIA GPUs, making it easier to write efficient and portable code.
CuTe provides Layout and Tensor objects that compactly packages the type, shape, memory space, and layout of data, while performing the complicated indexing for the user. This lets programmers focus on the logical descriptions of their algorithms while CuTe does the mechanical bookkeeping for them. With these tools, we can quickly design, implement, and modify all dense linear algebra operations. For example, a row-major MxN layout and a column-major MxN layout can be treated identically in software.
The core abstraction of CuTe are the hierarchically multidimensional layouts which can be composed with data arrays to represent tensors. The representation of layouts is powerful enough to represent nearly everything we need to implement efficient dense linear algebra. Layouts can also be combined and manipulated via functional composition, on which we build a large set of common operations such as tiling and partitioning.
For eye-watering levels of detail, refer to the CuTe documentation.
”What is happening right now?”
Triton programs are written for block-level parallelism, which is a common programming model for GPUs. This means that the programmer defines a kernel function that operates on blocks of data, and the GPU executes this function in parallel across multiple threads.
So you take the entire input space of the problem and map it to blocks that can be operated on in parallel. Each block is then divided into smaller threads, which can be executed concurrently. The choice of proper block tile size is crucial for performance, as it affects the amount of shared memory used and the number of threads that can be executed in parallel.
The Triton compiler is designed to optimize the execution of these kernels by analyzing the data access patterns and memory usage. It can automatically generate efficient code for different GPU architectures, taking advantage of the specific features and capabilities of each architecture. This automatic optimization process includes selecting the best block size, memory layout, and data access patterns for the given kernel function.
Triton Linear Layouts
In this article http://mlai.blog/2025-05-10-cute-basics#composed-layout-c—abi we saw how layouts can be composed in CuTe. Triton takes this a step further by introducing the concept of linear layouts, which are designed to work seamlessly with Triton’s programming model.
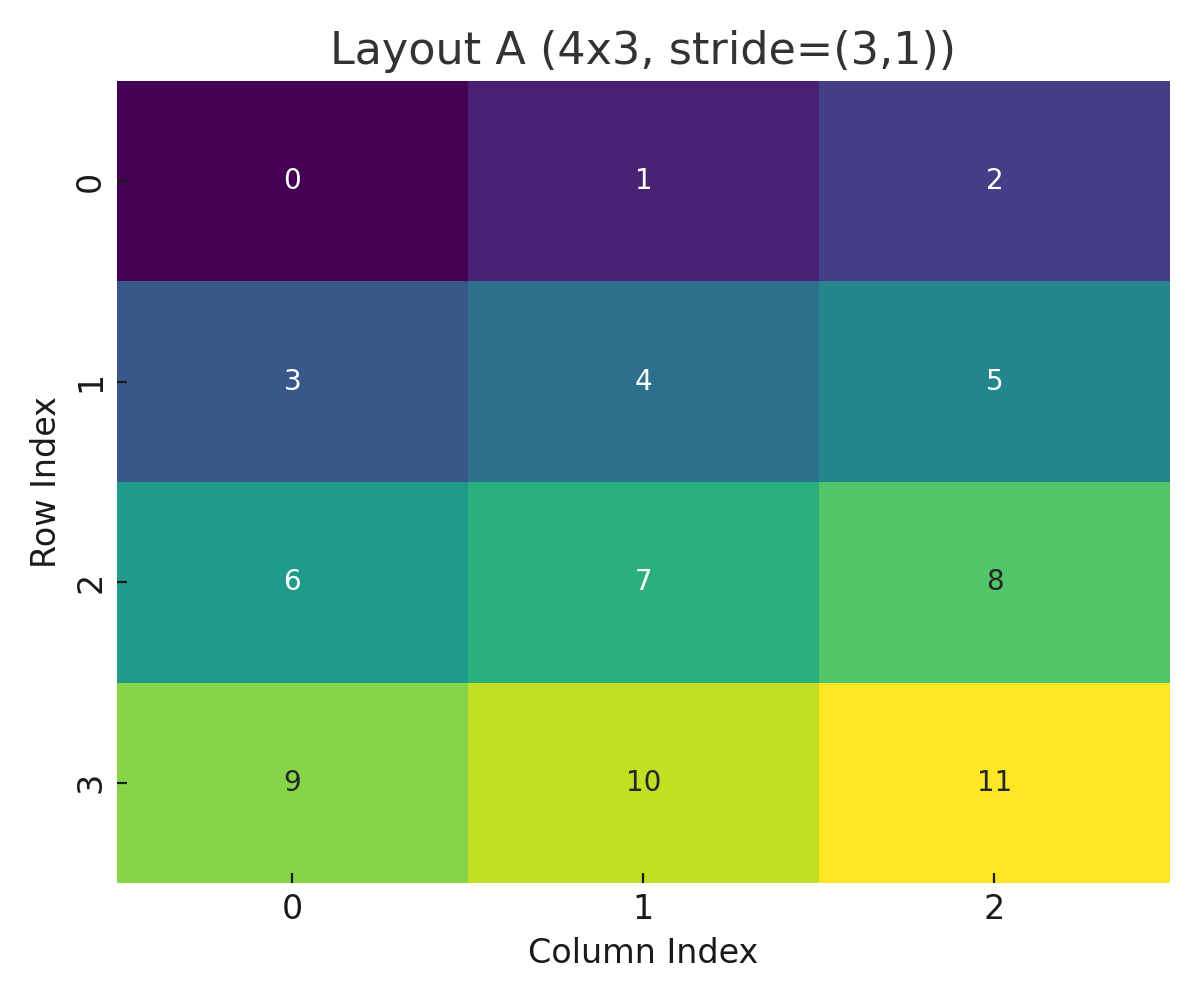
Layout A (4x3, stride=(3,1))
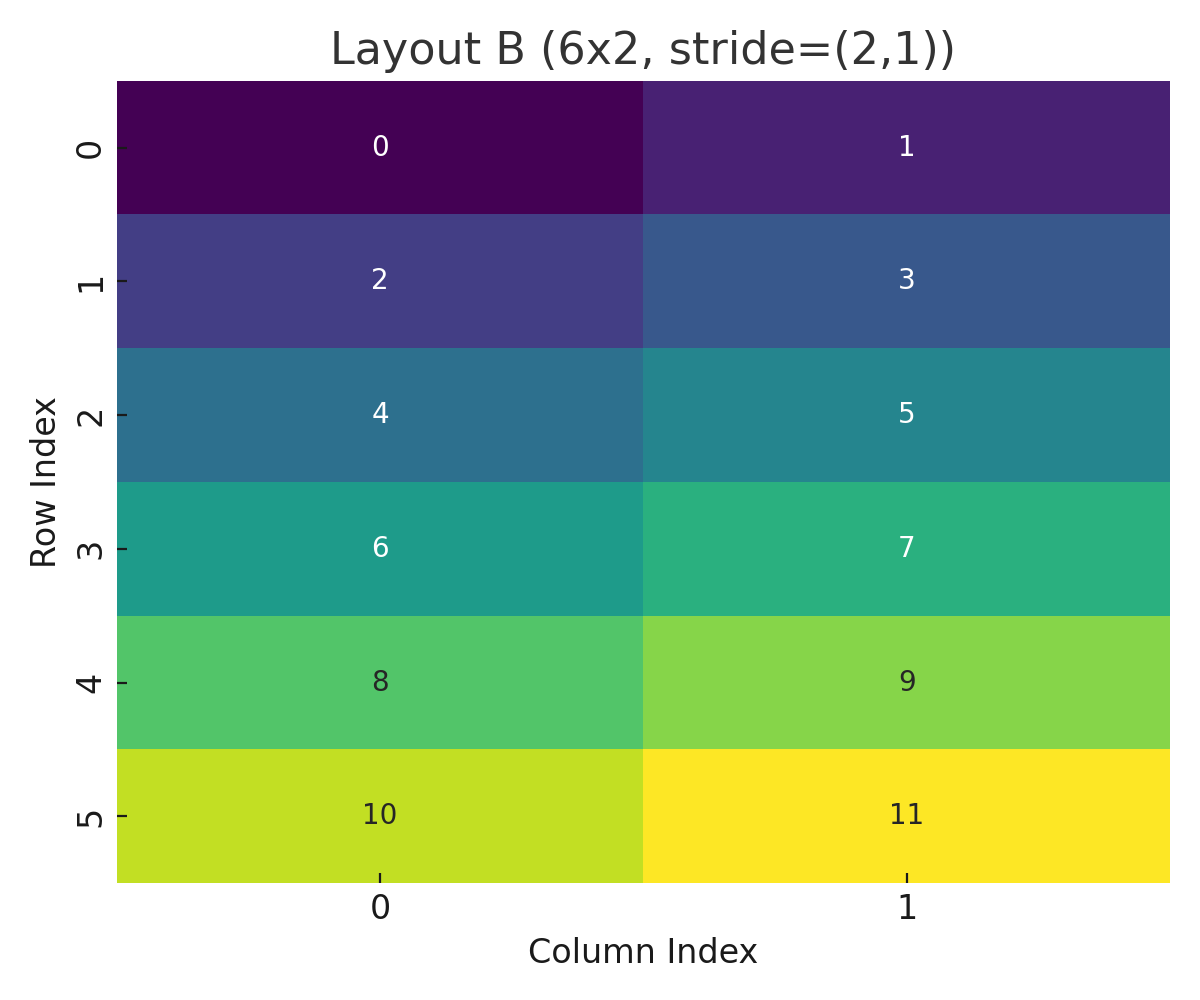
Layout B (6x2, stride=(2,1))
Composed Layout C = A(B(i))
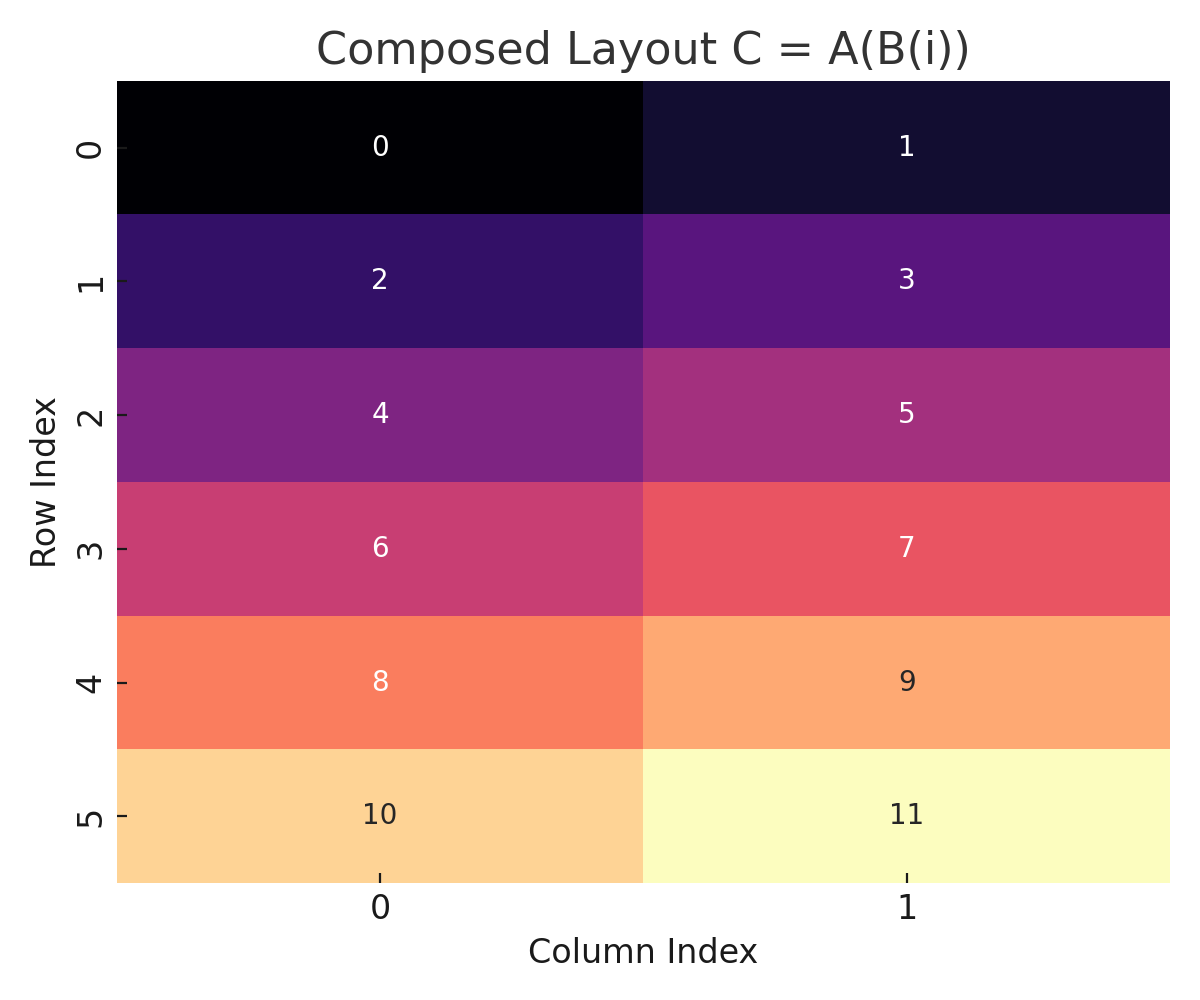
So what’s “Linear” about these Layouts? CuTe provides an “algebra of Layouts.” Layouts can be combined and manipulated to construct more complicated layouts and to tile layouts across other layouts. This can help users do things like partition layouts of data over layouts of threads.