CuTe Layouts, From Basics to Profiling
A hands-on walkthrough exploring layout algebra with CuTe and profiling GPU Memory Accesses.
Introduction
I recently got nerd-sniped by Nvidia’s announcement of Python support for CuTe / CUTLASS in GTC2025. So I will set out on a worklog to implement some SOTA Attention mechanism using CUTLASS / CuTe.
I recommend that you follow along with me and try to implement the following by yourself. For this worklog, I will use only RTX-4090. Although, at some point I might bite the bullet and level up to using H100/B200 etc.
Further, we will learn through implementing a specific set of tasks which will progressively level us up. The goal for this worklog is to implement one of the SOTA Attention Kernels in CUTLASS.
Part 1: Understanding Basic Layouts in CuTe
Task 1 – Row-Major vs Column-Major Layouts
CuTe uses a clean DSL for expressing tensor layouts. You can define layouts using:
make_layout(make_shape(...), make_stride(...))Row-Major vs Column-Major Example
auto rm_layout = make_layout(make_shape(4, 4), make_stride(4, 1));
auto cm_layout = make_layout(make_shape(4, 4), make_stride(1, 4));This yields the following visualization via cute::print_layout():
Row-Major (4,4):(4,1):
0 1 2 3
+----+----+----+----+
0 | 0 | 1 | 2 | 3 |
+----+----+----+----+
1 | 4 | 5 | 6 | 7 |
+----+----+----+----+
2 | 8 | 9 | 10 | 11 |
+----+----+----+----+
3 | 12 | 13 | 14 | 15 |
+----+----+----+----+
Column-Major (4,4):(1,4):
0 1 2 3
+----+----+----+----+
0 | 0 | 4 | 8 | 12 |
+----+----+----+----+
1 | 1 | 5 | 9 | 13 |
+----+----+----+----+
2 | 2 | 6 | 10 | 14 |
+----+----+----+----+
3 | 3 | 7 | 11 | 15 |
+----+----+----+----+
Part 2: Composition of Layouts
Task 2 – Composing Layouts C = A ∘ B
You can explore the idea of composing two layouts:
C(i) = A(B(i));Given:
auto A = make_layout(make_shape(6, 2), make_stride(8, 2));
auto B = make_layout(make_shape(4, 3), make_stride(3, 1));
auto C = composition(A, B);CuTe provides a helpful print_layout() to visualize this:
Layout A (6,2):(8,2)
0 1
+----+----+
0 | 0 | 2 |
+----+----+
1 | 8 | 10 |
+----+----+
2 | 16 | 18 |
+----+----+
3 | 24 | 26 |
+----+----+
4 | 32 | 34 |
+----+----+
5 | 40 | 42 |
+----+----+
Layout B (4,3):(3,1)
0 1 2
+----+----+----+
0 | 0 | 1 | 2 |
+----+----+----+
1 | 3 | 4 | 5 |
+----+----+----+
2 | 6 | 7 | 8 |
+----+----+----+
3 | 9 | 10 | 11 |
+----+----+----+
Composed Layout C
((2,2),(3,1)):((24,2),(8,2))
0 1 2
+----+----+----+
0 | 0 | 8 | 16 |
+----+----+----+
1 | 24 | 32 | 40 |
+----+----+----+
2 | 2 | 10 | 18 |
+----+----+----+
3 | 26 | 34 | 42 |
+----+----+----+
Validating C(i) = A(B(i))
for (int i = 0; i < size(C); i++) {
assert(C(i) == A(B(i)));
}All indices passed, confirming that CuTe composition behaves correctly.
Part 2b: Getting the Coordinate from a 1D Index
We learned that:
B(i)returns a memory offset, not a coordinate.- To get coordinates, use:
auto flat = coalesce(B);
auto coord = flat(i); // returns (row, col)We then manually verified:
C(i) == A(flat(i))for all valid i.
Part 3: Profiling Layout Access with Nsight Compute
Real CuTe Layouts from Task 2
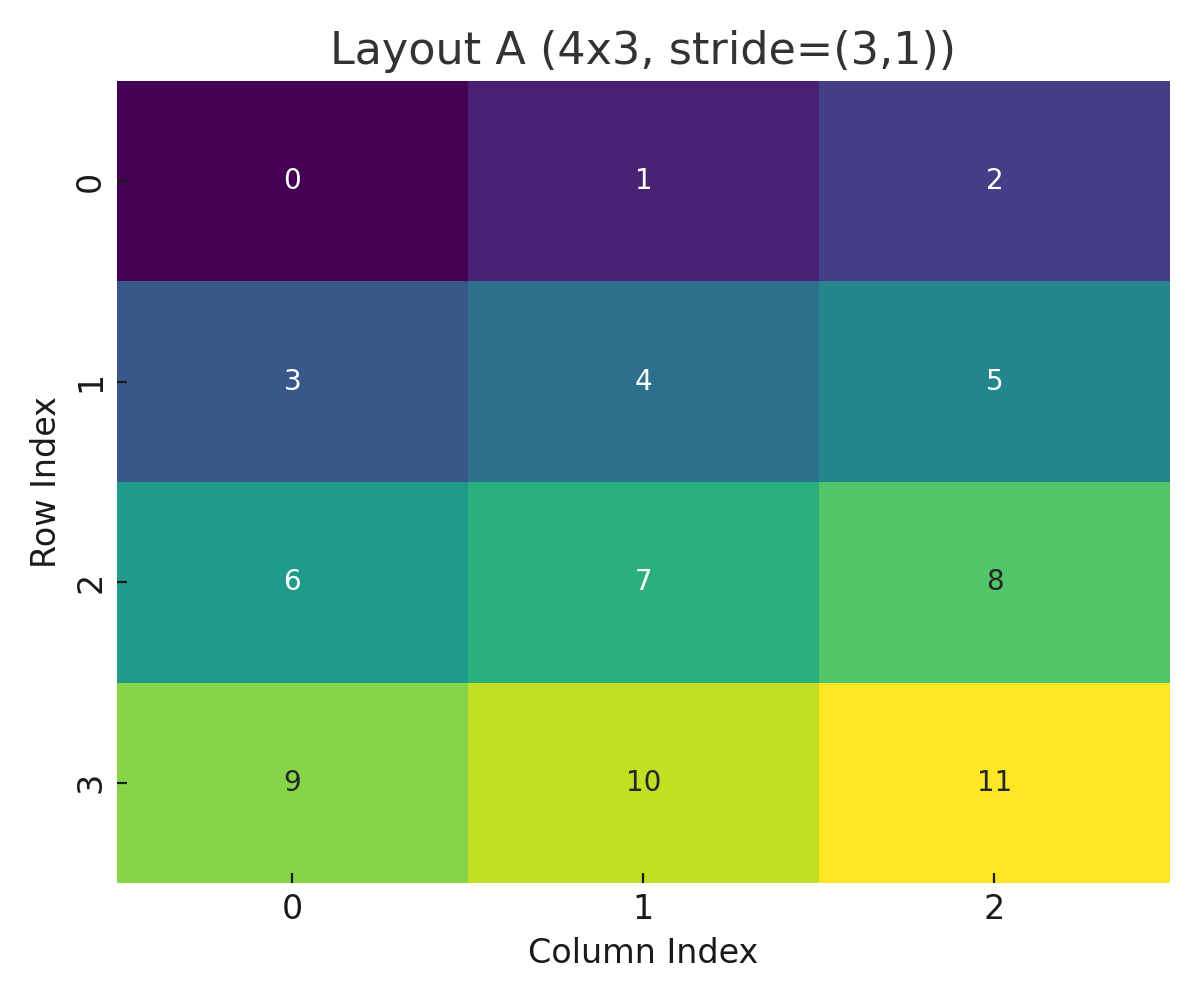
Layout A (4x3, stride=(3,1))
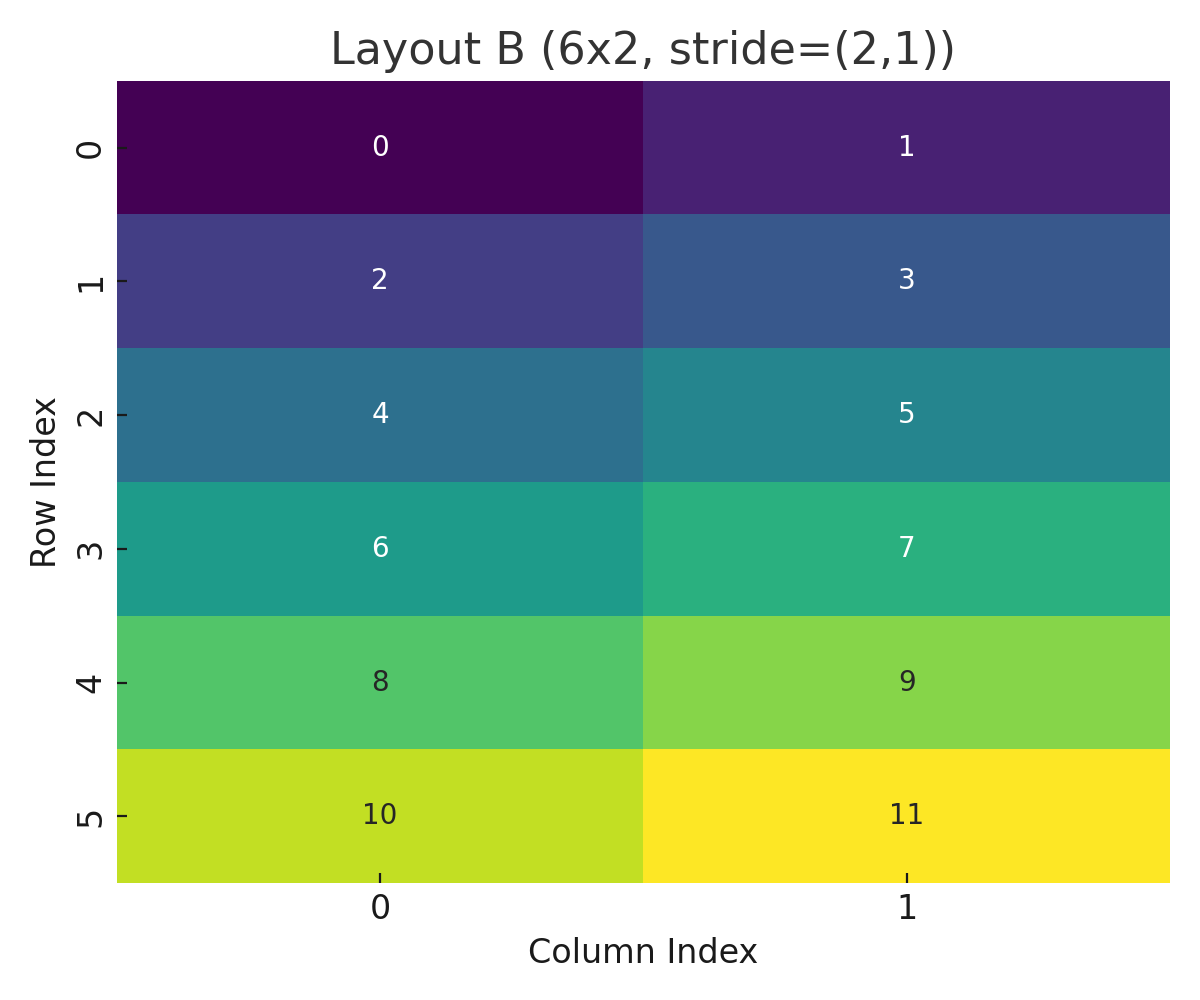
Layout B (6x2, stride=(2,1))
Composed Layout C = A(B(i))
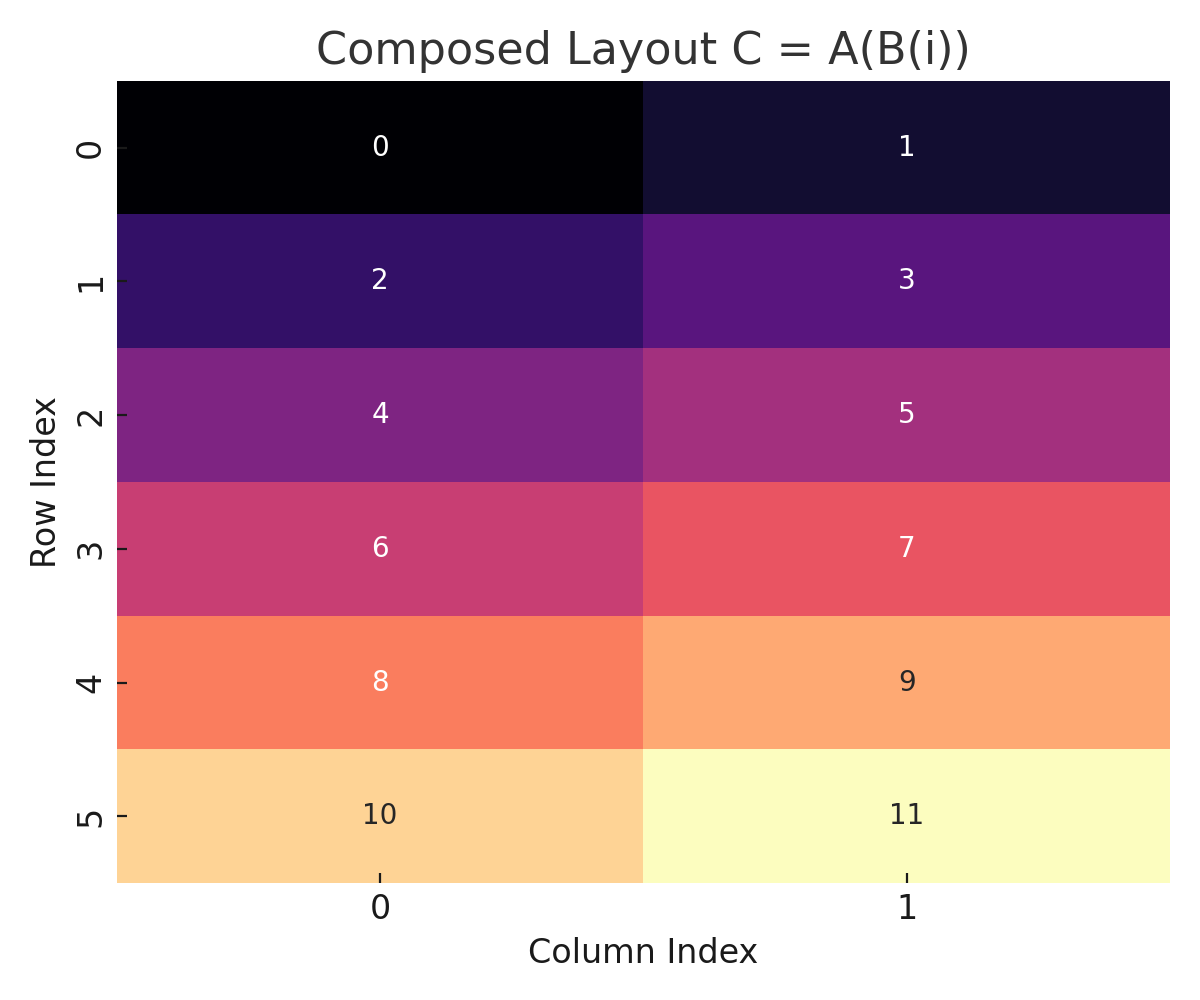
These plots show how CuTe translates coordinate systems and compositions into linear memory offsets.
Warp Divergence from Nsight Compute
Based on profiling data, we observed that an average of only 20.5 out of 32 threads were active.

This warp divergence visualization illustrates how thread-level control flow can impact GPU efficiency. Red bars represent inactive threads due to branching or predication, and green bars represent active threads.
These visualizations help illustrate how memory layout and access patterns impact performance and occupancy on the GPU. They are useful tools for understanding and optimizing low-level CUDA behavior.
Key Learnings
| Concept | Insight |
|---|---|
| Layout definition | make_layout(shape, stride) expresses memory patterns |
| Composition | C(i) = A(B(i)) holds if dimensionality matches |
| B(i) as offset | CuTe returns a scalar unless explicitly flattened |
| Coordinate extraction | Use coalesce(B)(i) to get (row, col) |
| Profiling | Requires an actual CUDA kernel to show up in ncu |
Up Next
In the next phase, we’ll explore:
- Batched layouts with 3D shapes
- How batching affects Memory Traversal and layout stride
- Start preparing for tiling and fused kernels in MLA
Related Concepts
Appendix
- Code examples: available in repo/task directory
- Reference: NVIDIA CuTe layout algebra PDF
- Python used only for generating scripts and plots from layout metadata.